
营销平台设计
抽奖策略领域和库表设计
抽奖功能拆分
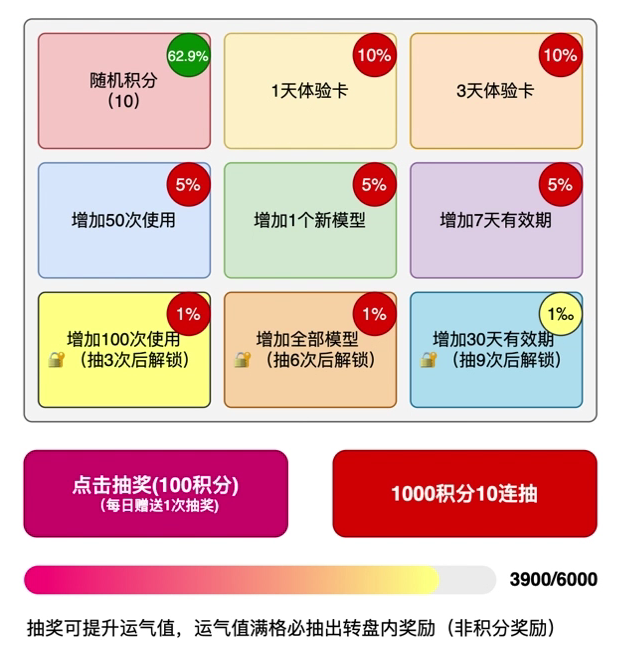
- 所有奖品整体概率相加,总和为1,概率范围千分位
- 抽奖为免费抽奖次数 + 用户消耗个人积分抽奖
- 抽奖活动含总库存,控制运营成本(可以配置无限制库存)
- 活动延申配置用户库存消耗管理,单独提供表配置各类库存,用户可用总库存,用户可用日库存
- 部分抽奖规则,需要抽奖n次后解锁,才有机会抽取
- 抽取完成增加运气值,让用户获得奖品
- 奖品对接,自身的积分、内部系统的奖品
- 随机积分,得到随机的积分奖励
策略概率装配处理
抽奖的算法一种是空间换时间,另外一总是时间换空间。映射到方案上,空间换时间,是提前计算好抽奖概率分布,用本地内存 guava 或者 redis 存储,最后抽奖的时候通过生成的随机值,在空间内定位即可,复杂度为O(1)。
但要注意,本地内存更快,Redis 相对慢一些。但 Redis 可以直接解决分布式存储问题,本地内存需要让多台分布式机器都保持数据的同步更新,需要引入配置中心以及定时检测的手段,来处理应用启动前/运行中,对活动新增/变更做本地内存做数据加载处理(大厂中一些非常高并发的场景,会申请内存更大的机器来做这样的事情)。
时间换空间,就是抽奖的计算,可以抽奖的时候生成一个随机值,之后和概率范围for循环比对。这样的场景适合那种需要,非常大的空间存放抽奖概率,不划算的时候,可以考虑这种。也可以在程序中设定,当总概率值超过100万,则不存储,而是改为循环比对。但,一切的手段,都要与实际诉求来依赖。
不超卖库存规则实现
当通过抽奖策略计算完用户可获得的奖品ID后,接下来就需要对这一条奖品记录进行库存的扣减操作。只有奖品库存扣减成功,才可以获得奖品ID对应的奖品,否则将走到兜底奖品。
首先对于库存集中扣减类的业务流程,是不能直接用数据库表抗的。
比如数据库表有一条记录是库存,如果是通过锁这一条表记录更新库存为10、9、8的话,就会出现大量的用户在应用用获得数据库的连接后,等待前一个用户更新完库表记录后释放锁,让下一个用户进入在扣减
这样随着用户参与量的增加,就会有非常多的用户处于等待状态,而等待的用户是持久数据库的连接的,这个连接资源非常宝贵,你占用了应用中其他的请求就进不来,最终导致一个请求要几分钟才能得到响应。【前台的用户越着急,越疯狂点击,直至越来越卡到崩溃】
所以,对于这样的秒杀场景,我们一般都是使用 redis 缓存来处理库存,它只要不超卖就可以。但也确保一点,不要用一条key加锁和等待释放的方式来处理,这样的效率依然是很低的。所以我们要尽可能的考虑分摊竞争,达到无锁化才是分布式架构设计的核心。
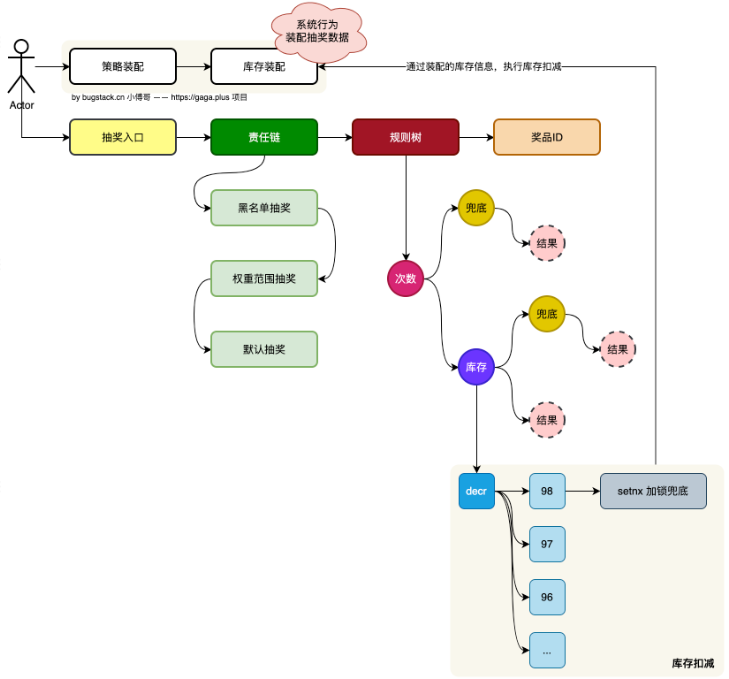
对于库存节点的操作,开发 decr 方式扣减库存。decr 是原子操作,效率非常高。这样要注意,setnx 加锁是一种兜底手段,避免后续有库存的恢复,导致库存从96消耗后又回到了98重复消费。所以对于每个key加锁,98、97、96… 即使有恢复库存也不会导致超卖。【
setnx在redisson是用trySet实现】库存消耗完以后,还需要更新库表的数据量。但这会也不能随着用户消耗奖品库存的速率,对数据库表执行扣减操作。所以这里可以通过
Redisson延迟队列的 + 定时任务的方式,缓慢消耗队列数据来更新库表数据变化。
抽奖API接口实现
这部分是由产品和前后端工程师对照着产品PRD文档进行评审后定义的。前端工程师按照标准先进行Mock接口,随着后端工程逐步开发完成后,在进行对接联调。
在大营销的系统架构设计中,有一个 trigger 模块,专门用于提供触发操作。这里我们把 HTTP 调用、RPC(Dubbo)调用、定时任务、MQ监听等动作,都称为触发操作。触发表示通过一种调用方式,调用到领域的服务上。
在大营销系统中,会给大家提供出 HTTP 接口,也会在后续提供 RPC 接口。RPC 就像 Dubbo 这样的框架,它的调用方式是需要对外提供接口描述性Jar,调用方拿到 Jar 包,就像本地调用接口一样,使用 RPC 框架,远程的调用到你的服务上。
为了让 HTTP 接口、RPC 接口,都能在一个标准下开发,所以本节会增加一个 big-market-api 模块,定义出接口信息和出入参对象。以便于分别可以实现本节所需的 HTTP 接口和后续所需的 RPC 接口。【注意;一般在大厂中,我们只需要定义 RPC 接口即可,因为 HTTP\小程序\APP 的接口,都是通过网关来调用的。网关会把 HTTP 请求转换为对应的 RPC 接口。
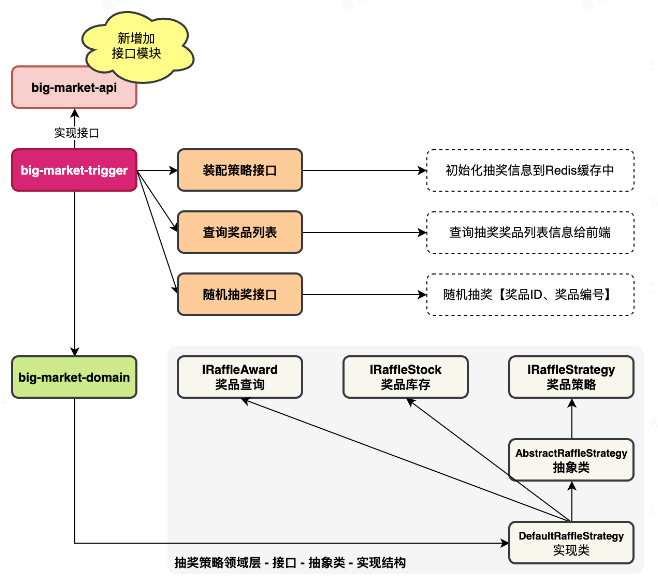
用户参与抽奖活动库表设计
在一个营销场景中,抽奖的流程分为;参与的有效期、整体的预算库存、个人的可参与次数、之后是抽奖策略的计算处理,返回抽奖结果。
大营销第1阶段已经完成了抽奖策略的领域模块实现,接下来则需要设计一个外壳,把抽奖策略包装进去。这个外壳就是一个抽奖活动的配置,在活动上有相关的库存、时间、状态,个人在总、日、月分别可进行的参数次数判断。
以用户参与大营销的抽奖活动为视角,来理解整个抽奖业务流程。
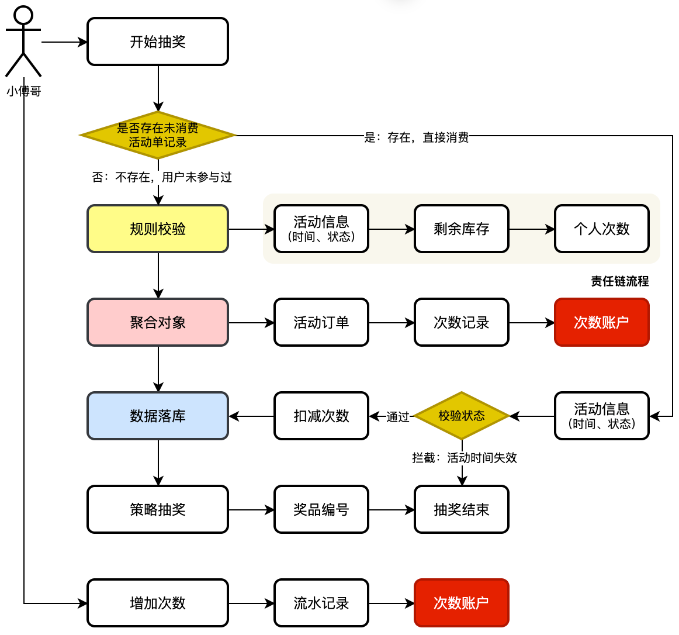
- 我们可以把用户参与抽奖理解为商城的一次下单,下单后才具备参与抽奖的资格。而下单的过程中,则需要过滤活动的相关信息以及库存数据。
- 所有的判断流程做完后开始写入库中,库中则是用户一个互动的次数账户记录。记录着用户可以参与的抽奖次数。同时需要把参与活动的记录写一条订单。
- 此外为了扩展用户在一些场景中,首次【签到/登录】可以赠送一个抽奖次数外,还可以通过购买、做任务、兑换等方式获得新的抽奖次数。这样用户就可以不断地消耗自己的积分兑换抽奖次数来抽奖了。
库表设计
两个活动配置表(抽奖活动表、参与次数表)、三个用户领取表(活动下单记录、活动次数账户、账户次数流水)
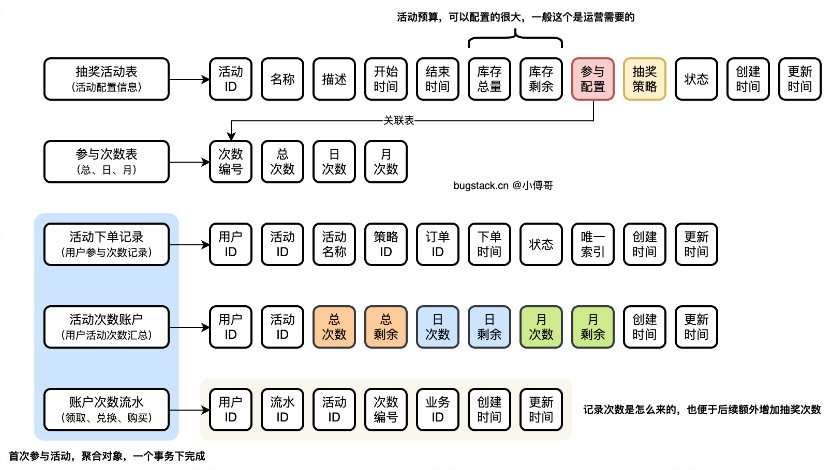
- 抽奖活动表,配置了用户参与一个活动的时候,需要进行的必要信息判断。时间、库存、状态等。
- 参与次数表,单独分离出来。这样更方便后续基于不同的次数编号,做扩展。比如兑换一个新的抽奖次数。
- 活动下单记录表,用户参与活动,则需要先创建一笔订单记录。如果用户抽奖中有失败流程,也可以基于订单的状态,用户重新发起抽奖,也不会额外占用库存记录。
- 活动次数账户表,记录着一个用户在一个活动的可参与次数数据,也就是个人活动账户。
- 账户次数流水表,每一笔对账户变动的记录,无论是任何的方式的变动,都要有一条流水。
引入分库分表路由组件
为用户的行为数据,使用路由组件将数据散列到分库分表中。
分库分表也是分布式架构中一个非常常用的数据存储方案,通常在公司中创建的系统都是直接创建出带有分库分表的系统架构。因为本身本身分库分表就是一个很成熟的方案,系统的分层和开发的熟练度都非常高。如果早期设计为单库单表的,那么后期再想扩展为分库分表则会有非常大的数据迁移和工程改造成本。
那么,分库分表以后,早期需要更多的数据库资源吗?其实并不用的,对于早期上线的系统,如果评估没那么大的体量,则可以使用虚拟机的方案安装数据库,也就是原来1台物理机,装1个数据库,现在则是2台物理机拆分为虚拟机,各个应用互相使用【作为主备】。而你占用的都是虚拟资源。也就是原来1台物理机等于5个虚拟机,现在5个虚拟机被分配到各个物理机上。所以你的分库分表并没有额外占用更多的资源。但这样的设计,业务体量上来以后,扩展只需要调整虚拟机的分配就可以了。
功能流程
在大营销的系统设计中,有一个配置库(big_market)和两个分库(big_market_01、big_market_02),我们需要对两个分库进行配置路由操作。达到分库分表的目的,而配置库则是一个单库单表存储活动等配置类信息。分库分表调用流程【如图】
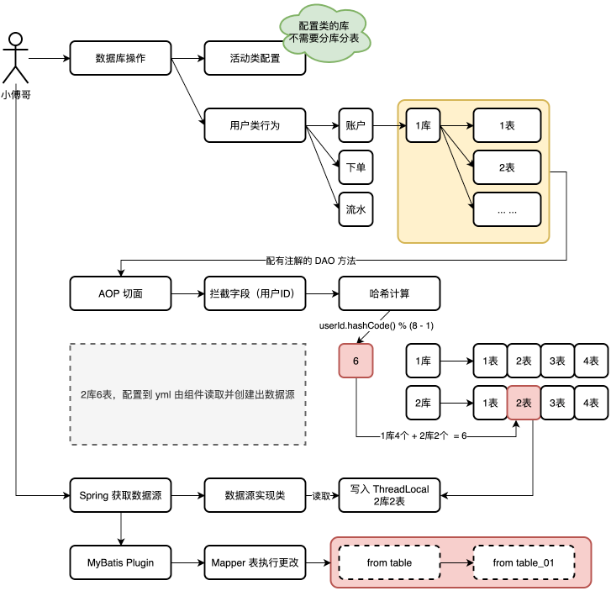
- 以用户对数据库的操作为视角,发生用户类的行为操作时【账户、下单、流水】,则会根据用户ID(userId)进行路由,把数据分配到x库y表中。
- 路由计算的处理,是以配置了 @DBRouter注解的 DAO 方法进行路由切面开始。通过获取用户ID(userId)值进行哈希索引计算。哈希值 & 2从n次幂数量的库表 - 1 得到一个值,在根据这个值计算应该分配到哪个库表上去。比如这个是6,分库分表是2库4表,共计8个,那么6就分配到了1库4+2库2个等于6,也就得到了2库2表。
- 对于计算得到的分库分表值,存入到 ThreaLocal 中,这个东西的目的是可以在一个线程的调用中,可以随时获取值,而不需要通过方法传递。
- 最后 Spring 在执行数据库操作前,会获取路由。而路由组件则实现了动态路由,从 ThreadLocal 中获取。此外注意,因为还有分表的操作,比如 table 需要为 table_01 这个动作是由 MyBatis Plugin 插件开发实现的。
关于数据库路由组件单独录制了课程,更多细节内容可以学习。**数据库分库分表路由组件** - 这个小组件足够写个简历项目用。
此外 sharding-jdbc 也可以做分库分表,但直接使用小伙伴们会错过理解分库分表的核心设计,所以我们这里选择使用星球「码农会锁」里的 DB-Router 进行分库分表。
数据源配置
# 多数据源路由配置,库数量 * 表数量 为2的次幂,如2库4表 |
- dbCount 分几个库,tbCount 分几个表,两个数的乘积为2的次幂。
- default 为默认不走分库分表时候路由到哪个库,这里是我们需要的配置库。
- routerKey 默认走的路由 Key,一个数据路由,是需要有一个键的,这里选择的是用户ID作为路由计算键。
- list: db01,db02 表示分库分表,走那套库。
- db00、db01、db02 就是配置的数据库信息了。这里给每个数据库都配置了对应的连接池信息。
抽奖活动订单流程设计
本节我们要设计出,用户参与抽奖活动的流程设计,并可以支持后续满足用户通过不同行为来增加自己的抽奖次数。
那么站在本节的诉求上,小傅哥将会带着读者对前面所设计的活动库表做一个解耦操作。来满足后续流程中个人可参与抽奖活动次数的变化处理。
功能流程
抽奖的行为理解为一个下单过程,用户参与抽奖,也等价于商品下单。只不过这个商品的 sku(库存量单位) 是活动信息。
SKU(Stock Keeping Unit,库存单位)是指用于管理和跟踪库存的唯一标识符。每个SKU对应一个具体的产品,并且通常包括该产品的所有特性,如品牌、型号、颜色、尺寸等。
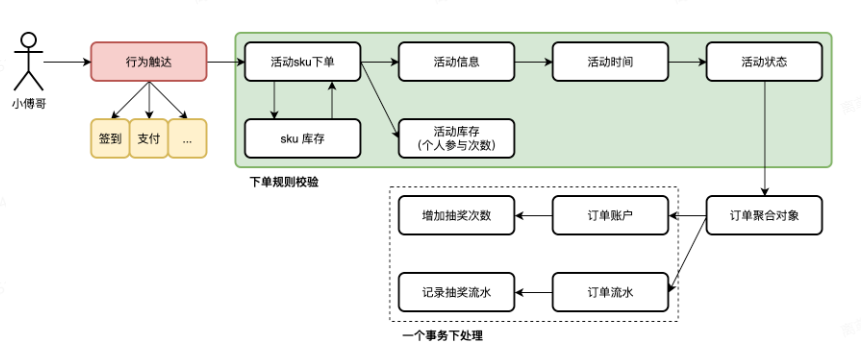
- 用户的触达行为是后续需要扩展的部分,当我们把大营销结合给其他系统的时候,就可以让支付后的消息推送过来,给用户领取一次抽奖次数。并参与抽奖。【还记得你在商城,或者一些云服务购买后,可以参与抽奖的过程吗?】
- 在上一节,小傅哥是把活动的可参与库存、用户的库存,都配置到活动本身。那这样就有一个问题,比如不同的场景,所需要在一个活动上给用户分配的抽奖次数不同,那么就不好配置了。所以我们要抽象一下,把活动和个人参与的次数,从活动配置中解耦出来,并通过 sku 商品表的方式配置出这样一组商品信息。
- 另外,在活动信息表中,还有活动的库存。这里我们把活动的库存也提取出来,放到 sku 上。一个商品的 sku 能下单多少次,由 sku 管理就行了。
库表调整
按照我们的功能流程设计,新增加 sku 表,并去掉分库分表中的 flow 流水表,而是直接由 order 订单表提供。
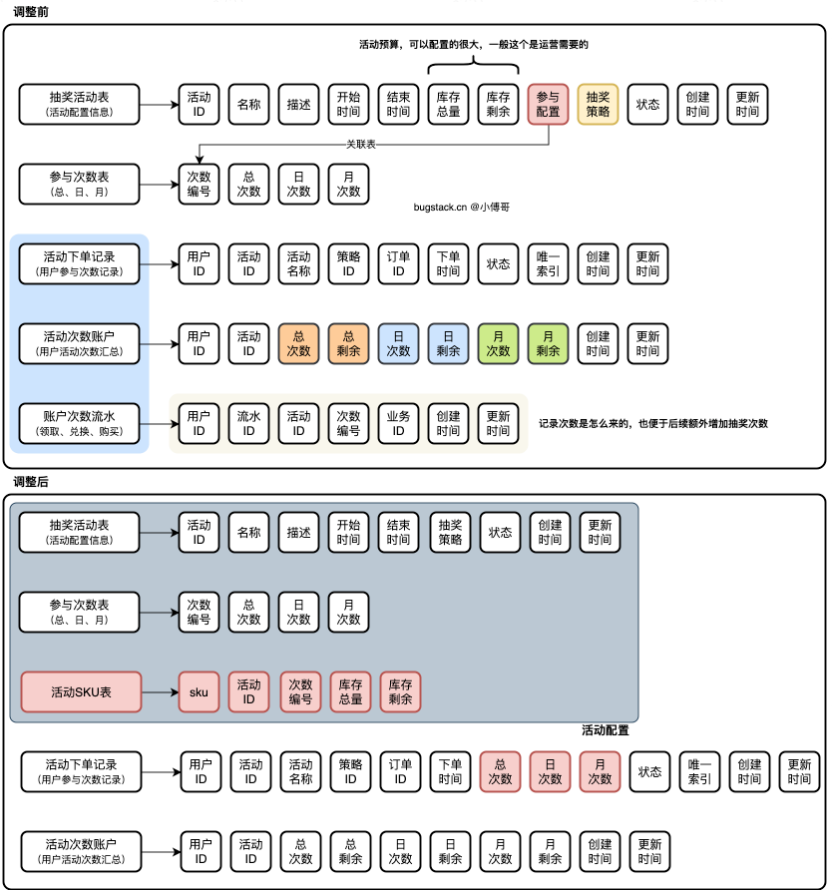
- 首先,去掉活动表中的关联操作,并新增加活动 sku 表来做关联。这样就可以把活动和参与次数当成一种物料,之后 sku 来定义库存或者将来想扩展价格或者积分兑换也是可以的。
- 之后,去掉原来的次数流水表,把流水的用途合并到订单表中。想获得更多的抽奖次数,就直接对 sku 下单即可。无论是通过赠送、签到、打卡、积分兑换等任何方式,都是可以的。这样也就增强了营销活动的扩展性。
- 注意:调整的库表信息,已经放到了导出sql语句,放到本节分支下 docs/dev-ops/mysql/sql 下。




